Jérôme Euzenat, François Rechenmann
INRIA Rhône-Alpes - IMAG-LIFIA, 46, avenue Félix Viallet,
38031 Grenoble, France
Jerome.Euzenat@imag.fr,Francois.Rechenmann@imag.fr
Il y a dix ans, apparaissait le système de représentation de
connaissance Shirka. À travers la présentation de sa conception,
de son évolution et de son utilisation, on tente d'établir ce que
peut être, dix ans plus tard, un système de représentation
de connaissance. La mise en oeuvre de deux points clé de Shirka -- la
séparation programmation-représentation et l'utilisation de
l'objet partout où cela est possible -- est particulièrement
étudiée. Ceci permet de considérer leur pertinence et leur
évolution pour la représentation de connaissance.
Sommaire
- Contexte
- Le modèle de Shirka
- Le noyau de représentation
- Interprétation
- Mécanismes d'inférence
- Développements ultérieurs
- Règles
- Système de maintien du raisonnement
- Classification
- Langages de tâches
- Hypertexte
- Applications
- Tropes
- Conclusion
- Références
10 ans approximativement après son implémentation initiale, le
logiciel Shirka est toujours utilisé. Avant de nous demander si cela est
trop ou trop peu, nous revenons sur ces années de travaux autour de
Shirka et essayons d'en tirer des enseignements pour le futur et en particulier
pour son successeur Tropes.
L'exposé suivant ne correspond pas à ce qui aurait
été écrit il y a quelques années: la meilleure
compréhension du système et le souci de faire partager cette
compréhension là, et non celle de l'époque, interdisent de
décrire Shirka dans les termes
initiaux. Du reste, le manuel [
Rechenmann& 88] est toujours disponible.
Le contexte dans lequel Shirka a été créé est
d'abord présenté. Puis, l'exposé porte sur le noyau
initial de Shirka, ses extensions ultérieures et ses applications.
Après cela les différents aspects conservés ou
abandonnés dans Tropes sont abordés.
La première version de Shirka était disponible en 1984
[Rechenmann& 84], c'est-à-dire:
- une quinzaine d'années après le début des langages de
programmation à objets, alors que SmallTalk en était le seul
représentant ayant une visibilité importante;
- une dizaine d'années après les écrits sur les
"frames" de Marvin Minsky [Minsky 74];
- quelques années après les langages de représentation
de connaissance FRL [Roberts& 77],
KRL [Bobrow& 77],
Loops [Bobrow& 81] ou
SRL [Wright& 83];
- À la suite des premiers articles de Ronald Brachman sur la
rationalisation de la représentation de connaissance [
Goodwin 79;
Brachman 1979, 1983, 1985];
- Au même moment que les systèmes commerciaux Art
[Williams 1984] et Kee [
Fikes& 85] et que les premiers
articles sur KL-one [Brachman& 85];
- Au même moment qu'un foisonnement de systèmes
développés en France et en Europe: Ceyx [Hulot 83],
Mering [Ferber 83], Kool [
Albert 84], LRO2 [Roche 84],
Smeci, Yafool [Ducournau& 86].
Le contexte semble donc
à l'implémentation des résultats des recherches
précédentes et à la rationalisation des formalismes de
représentation de connaissance. Shirka naît de
préoccupations de modélisation dans le domaine de la
biométrie et de la dynamique des populations. L'idée de
créer un système de représentation de connaissance par
objets vient de la lecture du chapitre 22 de la première version de
[Winston& 81] qui décrit les "frames". Il doit aussi beaucoup
à [Aikins 83] et à l'insistance de Jacques Pitrat et de
ses étudiants sur la déclarativité [
Laurière,
1982]. En effet, la volonté était dès le début de
ne pas mélanger langage de programmation et langage de
modélisation. Cette volonté résultait des travaux
menés antérieurement sur les langages de modélisation de
phénomènes dynamiques, en particulier en économie et en
biologie, dans lesquels trop souvent les éléments de description
d'un système dynamique se retrouvaient mélangés aux ordres
de simulation du modèle mathématique. C'est sans doute à
partir de ce parti-pris, souligné par le vocable
<<centré-objet>> destiné à marquer
l'opposition avec <<orienté-objet>>, que Shirka se
démarque des expériences menées à la même
époque. Cet aspect est visible dans la présentation des
attachements procéduraux, puis des tâches, où cette
séparation est très nette.
La conception et l'évolution de Shirka ne se sont cependant pas faits
dans l'ignorance des autres efforts menés à la même
époque. En particulier, le second parti-pris de Shirka, celui de pousser
jusqu'au bout le <<tout est objet>>, n'est pas étranger aux
travaux concernant les langages de programmation par objets.
La seconde version de Shirka, celle distribuée actuellement, a
été implémentée en 1986 par François
Rechenmann, Jose-Luis Aguirre et Didier Bloch. C'est elle qui est
décrite dans la suite. Enfin, pour ce qui concerne l'environnement
informatique, Shirka été
développé en Le-Lisp
[Chailloux 83] sur Apple Lisa, puis porté sur des stations Unix.
Initialement, Shirka [
Bensaid& 86;
Rechenmann 1985;
& 84;
88;
Rechenmann&89] tire des "frames" la notion de facette, des langages "post-frames" la
rationalisation des facettes et leur utilisation quasi-exclusive à des
fins de typage et d'inférence. Il tire aussi des langages de
programmation par objets l'idée du <<tout objet>> et d'une
implémentation réflexive où le système
lui-même est représenté en terme d'objets
[Cointe 85]. Mais le langage se démarque de ses semblables de
l'époque par l'absence d'envoi de messages et, plus
généralement, par un abandon de tout ce qui concerne la
programmation pour se concentrer sur la représentation.
Le noyau central du système a peu évolué; il est possible
de le décrire en trois temps: les objets, les classes et la
spécialisation. Un objet est un nom auquel est associé un
ensemble de valeurs d'attributs, ces valeurs pouvant être d'autres objets
(comme dans SmallTalk, toutes les valeurs primitives -- réels, entiers
ou chaînes -- sont considérées comme des objets). Le
langage permet de décrire un objet de la manière suivante
([[iota]] dénote l'absence de valeur, la ligne correspondante
n'apparaît alors pas dans le source):
{AutoDeSarah
est-un = Auto;
couleur = rouge;
puissance-fiscale = 9;
moteur = {Moteur#172
est-un = Moteur;
cylindrée = 2000};
puissance-réelle = [[iota]]}
Une
classe décrit un ensemble d'objets et pour ce faire elle
énumère la liste de ses attributs ainsi que leur type. Le type
d'un attribut est défini au moyen de facettes (voir table 1). Enfin la
classe détermine aussi des contraintes que doivent vérifier ses
instances.
Ainsi, la classe Auto peut-elle se définir comme une
sous-classe de Véhicule dont les attributs couleur,
puissance-fiscale et puissance-réelle sont
respectivement réduits à un symbole parmi
rouge, vert ou bleu, un entier entre
1 et 12 et un réel:
{Auto est-un Classe
sorte-de = Véhicule;
couleur $un symbole
$domaine rouge vert bleu;
puissance-fiscale $un entier
$intervalle [1 12];
puissance-réelle $un réel
$sib-exec
{calc-puissance
auto $var<- lui-même;
puissance $var-> puissance-réelle}}
La
spécialisation d'une classe par une autre permet de définir une
classe comme un ensemble d'objets dont les éléments ont une
structure plus spécifique que ceux de la sur-classe. Cette
spécificité s'exprime par un ensemble d'attributs plus grand et
par des types plus restreints pour les attributs déjà existants.
facette valeur interprétation restriction
[I(d)]
[[tau]] [[tau]], [[tau]]* [[tau]]=entier,
chaîne...
$un, $liste-de f E(f), E(f)* f est un filtre
c I(c), I(c)* c est une classe
$domaine v1... vn t[[intersection]] t est le type
{v1... vn } initial de
$sauf v1... vn t--{v1... vn } l'attribut
$valeur v t[[intersection]]
{v}
$card n {v[[propersubset] (pour $liste-de)
]t; |v|=n}
$intervalle [n1 n2] {v[[propersubset] (pour entier ou
]t; n1<=v<=n2} réel)
$a-verifier p
TAB.
1 - Facettes de typage. Une première facette ($un/$liste-de)
permet de spécifier le type ou la classe de la valeur. Un ensemble de
facettes permet de restreindre ce type initial (seconde partie du tableau). La
facette $a-verifier s'applique à un attribut qui peut
être l'attribut lui-même, permettant de porter sur l'objet
tout entier. La seconde colonne donne le type de valeur autorisée pour
la facette; la troisième donne l'effet de la facette sur le domaine de
l'attribut (voir ci-dessous). * dénote la séquence.
Shirka est avant tout un programme et n'a pas été pourvu
d'emblée d'une sémantique formelle. Cependant, ses concepteurs
ont tenté de n'y utiliser que des concepts dont la signification soit
suffisamment stable et raisonnée pour être rapidement
intelligible. Une ébauche de traitement formel du langage utilisé
permet de justifier le fonctionnement de Shirka (dans ses grandes lignes, car
quelques points restent rebelles tels que le traitement erratique des listes).
Ainsi, partant d'un domaine du discours D, on peut établir
l'ensemble des valeurs possibles d'attributs en y ajoutant les valeurs
primitives (entiers, réels, chaînes...) ce qui correspond à
l'ensemble D'. En y appliquant les constructeurs disponibles dans le
langage ($un et $liste-de), on obtient le domaine
D"=D'[[union]]D'* (c'est-à-dire contenant D' et
toutes les séquences d'éléments de D').
Les objets s'interprètent comme des éléments du domaine
(D), les classes comme des parties de ce domaine, les attributs comme
des fonctions partielles d'un élément du domaine vers une valeur
et les contraintes (ou prédicats) comme des n-uplets de valeurs
(un élément de D"). La fonction d'interprétation
I est alors telle que:
- (I(o)=I(o')
=> o=o')
- pour toute classe c, I(c)ÍD
- pour tout attribut f,
I(f):D->D'
pour tout prédicat p d'arité n,
I(p)ÍD"n (pour simplifier, on
considérera que les prédicats utilisés dans les objets
prennent en valeur l'objet lui-même; leur interprétation est donc
un sous-ensemble du domaine).
Par ailleurs, à chaque facette d est associé un domaine
I(d)ÍD" qui correspond à la colonne 3 de la
table 1. Les sous-ensembles correspondant aux classes subissent les contraintes
suivantes:
- pour toute sous-classe c'
de c (noté c'<=c), I(c')ÍI(c)
- pour toute instance o de c,
I(o)[[propersubset]]I(c)
pour toute de facette d d'un attribut
f de c,
I(f):I(c)->I(d)
Ainsi, la contrainte portant sur une classe est la suivante:
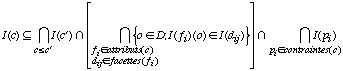
Le premier terme correspond à ce qui est réalisé en terme
opérationnel par le mécanisme d'héritage (l'inclusion de
l'interprétation d'une classe dans l'intersection de celle de ses
sur-classes), le second à la prise en compte de toutes les restrictions
sur les attributs de la classe et le dernier à la restriction aux objets
satisfaisant les prédicats (utilisés par les facettes
$a-verifier). Le caractère particulier de cette
présentation par rapport à d'autres présentations plus
classiques (telles que celles des logiques terminologiques) provient de la
présence de relations d'inclusion au lieu d'égalité entre
les termes. Ceci correspond à l'interprétation descriptive (et
non définitionnelle) des classes qui ne sont décrites que par des
conditions nécessaires à leur appartenance mais pas
forcément suffisantes.
Shirka travaille donc constamment avec deux termes: I(c)
représentant l'interprétation réelle des classes qui ne
lui est connue qu'au travers des instances et E(c) qui
représente l'extension maximale de cette interprétation,
c'est-à-dire le second terme de l'inéquation ci-dessus. Elle se
simplifie donc en I(c)ÍE(c).
Une classe décrit aussi, à l'aide de facettes, des moyens
permettant d'obtenir la valeur d'un attribut lorsqu'elle n'est pas connue (voir
table 2).
facette valeur
$sib-exec méthode
$sib-filtre filtre
$var<- ($var-liste<-) nom-d'attribut
$defaut valeur
TAB.
2 - Les facettes d'inférence et le type de leur valeur.
Les mécanismes d'inférence mis en oeuvre par Shirka se
distinguent par leur intégration profonde dans le langage de description
de classes. Ainsi, même le mécanisme le plus étranger,
l'attachement procédural, fait l'objet d'une présentation toute
Shirkaïenne (inspirée de SRL). Plus surprenant, l'exécution
de cet attachement est aussi très intégrée: un attachement
procédural est décrit par une classe (sous-classe de
méthode) dont les attributs sont les entrées/sortie et
un attribut particulier (fonction) contient le nom de la
fonction Lisp
associée à l'attachement procédural. Lorsque cet
attachement apparaît dans la description d'une classe (par exemple, pour
l'attribut puissance-réelle de la classe Auto, plus
haut) une sous-classe est créée enregistrant comment sont
obtenues les entrées/sortie (ici l'objet lui-même est
l'entrée et la sortie sera la valeur de l'attribut
puissance-réelle). Enfin, l'exécution de l'attachement
se passe comme suit: lorsque la valeur de l'attribut
puissance-réelle est demandée, le système
instancie cette sous-classe, renseigne les attributs d'entrée à
l'aide des méthodes correspondantes, applique la fonction
désignée à l'instance, récupère le
résultat dans l'attribut de sortie (s'il s'y trouve) et le retourne.
Un autre mécanisme encore plus intégré est le filtrage. Il
permet de chercher des instances ayant certaines caractéristiques. Un
filtre est en fait défini exactement comme une classe. Ainsi, on peut
implémenter la règle <<L'ensemble des fils d'un homme est
l'ensemble des hommes qui l'ont pour père>> par le filtre suivant
la facette $sib-filtre:
{Homme
est-un = Classe;
sorte-de = Personne;
lui-même $var lui;
père $un Homme;
fils $liste-de Homme
$sib-filtre
{Homme
père $var<- lui;
lui-même $var-> fils}}
Un
tel filtre retourne la liste des objets qui le satisfont (sans distinguer entre
objets qui ne peuvent le satisfaire et ceux qui sont incomplets comme dans
Yafool).
Shirka fut conçu comme un système de gestion de bases de
connaissance, c'est-à-dire permettant d'exprimer la connaissance sachant
qu'elle doit être manipulée par des programmes créés
pour une tâche précise. Il a donc été
développé, au dessus de Shirka, un certain nombre de
mécanismes de manipulation de bases de connaissance (ce que l'on ne
trouve pas dans les langages de programmation par objets qui considèrent
que n'importe qui peut implémenter ce dont il a besoin dans le
système). Ainsi, ces extensions ont implémentés des
développements successifs de la recherche en représentation de
connaissance. Certaines sont maintenant indissociables de Shirka
(classification), alors que d'autres n'ont que peu (TMS) ou jamais
(règles, introduction de nouvelles classes) été
utilisées réellement.
Si Shirka a su résister à la pression de la programmation, il n'a
pas pu résister à celle des règles. À une
époque où elles étaient quasi-indissociables des
<<systèmes-experts>> et à l'instar de Kool, Smeci ou
Yafool, il fallait bien que Shirka soit doté d'un système de
règles. Plusieurs expériences ont été
tentées: Crika [
Rechenmann&
85], Soli [Act 87] et
[Jean-Marie& 87]. Un effort d'intégration de ces
règles à Shirka a été consenti; en particulier dans
le dernier exemple, les règles sont représentées par des
objets comme c'était le cas à l'époque. Mais le
développement de Shirka allait plutôt vers la promotion de
mécanismes d'inférence spécifiquement objet et
profondément intégrés dans le système (attachement
le moins procédural possible, filtrage, classification, tâches).
Ces systèmes de règles n'ont pas fait fortune (ils n'ont pas non
plus été distribués avec le système).
Un système de maintien du raisonnement à propagation
[Doyle 79] a été ajouté à Shirka de
manière à conserver le résultat des inférences au
lieu de les refaire constamment [
Euzenat& 87]. Grâce
à un réseau de dépendances, il est capable d'invalider les
inférences qui ne sont plus valides lors de la modification d'une valeur
d'attribut, d'une classe ou de l'ajout d'une méthode. Deux remarques
peuvent être faites sur ce système: il a été victime
du principe du tout objet (le réseau de dépendances était
implanté en Shirka) ce qui nuit à ses performances, mais il a
très bien fonctionné dans la seule application qui l'ait
utilisé [Buisson 90b]. Les études théoriques faites
à ce propos [Buisson& 92] furent sans
ambiguïté: l'apport du TMS dans les performances était
crucial pour le système. Il n'a jamais été
intégré aux versions de Shirka distribuées (bien qu'il
soit possible de le débrayer).
La classification a été introduite dans
Shirka en 1987 [
Procop& 87;
Haton& 91]. Elle n'a, depuis lors,
pratiquement pas été modifiée. Ce mécanisme
était à l'époque très rare dans un langage de
représentation de connaissance diffusé. Classer une instance
i sous une classe c, c'est trouver les sous-classes de c
auxquelles i peut appartenir compte tenu des valeurs des attributs de
i. Une partition des classes en trois ensembles est alors obtenue
([[tau]]f,c est le type de l'attribut f dans la classe
c, valeur?(i,f) est la valeur de l'attribut f pour
l'instance i et [[iota]] dénote la valeur inconnue):
- Possibles: si toutes
les valeurs d'attributs de l'instance satisfont les contraintes de la classe:
[[universal]]f[[propersubset]]attributs(c), valeur?(i,
f)[[propersubset]][[tau]]f,c,
- Inconnues: si aucune
valeur d'attribut de l'instance ne viole une contrainte de la classe mais
certaines valeurs d'attributs sont inconnues:
[[universal]]f[[propersubset]]attributs(c), valeur?(i,
f)[[propersubset]][[tau]]f,c[[union]]{[[iota]]},
- Impossibles: s'il
existe une valeur d'attribut de l'instance qui viole une contrainte de la
classe: [[existential]]f[[propersubset]]attributs(c), valeur?(i,
f)[[reflexsubset]][[tau]]f,c[[union]]{[[iota]]}.
À partir de deux
définitions d'interprétation (correspondant aux ensembles
I(c) et E(c) de la définition des classes),
la classification est la recherche des classes auxquelles une instance pourrait
appartenir en respectant E(c) (c'est d'ailleurs une
opération duale du filtrage qui recherche les instances pouvant
appartenir à une classe). Cette caractérisation de la
classification a été donnée dans le formalisme des
systèmes classificatoires [Euzenat 93a] qui permet
d'établir que les propriétés associées à
Shirka (interprétation descriptive, pas d'exhaustivité) ne
permettent pas d'assurer que la classification rendra toujours un ensemble de
classes possibles muni d'un unique plus petit élément, ni que ses
plus petits éléments feront forcément partie des feuilles
de la taxonomie.
La classification de Shirka -- que l'on pourrait nommer identification --
possède un certain nombre d'originalités (sans égal
à l'époque à notre connaissance pour la classification
symbolique, on peut en trouver un équivalent dans CLASSIC [
Granger,
1988]):
- Elle prend en compte l'incomplétude des objets (le classement
d'instances incomplètes apparaît dans l'ensemble Inconnues).
- Parallèlement aux langages terminologiques qui ne s'autorisent pas
à classifier dans les concepts primitifs (correspondant à
l'interprétation descriptive des classes), Shirka dispose d'un
mécanisme de classification agissant uniquement dans des concepts
primitifs. Cependant, par rapport aux langages terminologiques, la
classification est plus simple puisqu'elle ne classe que des individus
(l'extension aux classes a été conçue et
implémentée [Capponi 94b], mais non distribuée).
- L'algorithme prend récursivement en compte la
<<classifiabilité>> des objets placés en valeurs
d'attributs dans la classe caractérisant le type de l'attribut. Un
utilisateur demandant une classification dans Shirka peut la voir se
dérouler en temps réel et examiner les trois ensembles sur le
graphe de spécialisation lui-même.
Cette classification
mériterait le traitement formel qui lui fait défaut quant
à la décidabilité et complexité du problème,
la complétude et la complexité de l'algorithme utilisé. On
peut considérer que l'implémentation <<naïve>>
de l'algorithme devrait conduire à une complexité exponentielle.
Cependant, les nombreuses applications utilisant la classification ne semblent
pas gênées par cela. Des travaux sont en cours pour établir
un algorithme dont la complexité temporelle devrait être
polynomiale pour une complexité spatiale linéaire.
Les travaux sur l'utilisation de bases de connaissance pour exploiter les
bibliothèques de programmes existants ont conduit à la notion
d'environnement de résolution de problèmes. Dans le cadre de
Shirka, c'est la notion de tâche qui s'est trouvée la meilleure
instanciation de ce principe. Les tâches apparaissent à la
croisée de différentes réflexions comme:
La notion de tâche exécutable a
donnée lieu à deux implémentations successives au dessus
de Shirka: Scai [
Poncabaré& 91] et Scarp (Système Coopératif d'Aide
à la Résolution de Problèmes [
Willamowski 94b;
& 94]).
Ce sont les principes du second qui sont --
très brièvement -- présentés ici.
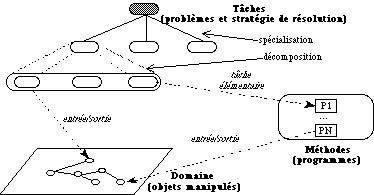
FIG. 1 (d'après [
Willamowski& 94]) - L'organisation
des entités dans un environnement de résolution de
problèmes. Les tâches sont reliées entre elles par la
spécialisation et la décomposition. Elles prennent en
entrée et produisent en sortie des objets du domaine
(représentés par des objets Shirka). Elles se résolvent
finalement en tâches élémentaires exécutables
prenant les mêmes entrées/sorties.
Une tâche définit un problème à résoudre.
Pour cela elle utilise une représentation qui se partage en:
- ses entrées (les données à traiter) qui sont
exprimées sous formes d'objets ou de valeurs;
- ses sorties (le résultat à obtenir) qui sont
exprimées sous formes d'objets ou de valeurs;
- une stratégie de résolution (les tâches sans
stratégie étant inapplicables).
Les tâches sont
décrites par des classes. Elles appartiennent donc à une
hiérarchie de spécialisation dans laquelle plus une classe est
spécialisée plus elle permet de résoudre un
problème précis. Cette précision s'exprime alors par un
affinement des entrées et des sorties du système ainsi qu'une
adaptation plus poussée de la stratégie de résolution. La
stratégie de résolution d'une tâche peut être
principalement de deux natures:
- un programme exécutable (la tâche est alors qualifiée
de méthode) qui résout le problème; ces tâches
permettent en particulier d'intégrer des bibliothèques de
programmes externes [
Prevosto& 89a,
b,
91;
Bassot 94a,
b];
- une décomposition en fonction d'autres tâches construites
à l'aide d'opérateurs classiques de programmation
(séquence, itération, choix, parallélisme...) et des flots
de données entre les entrées et sorties des tâches
impliquées.
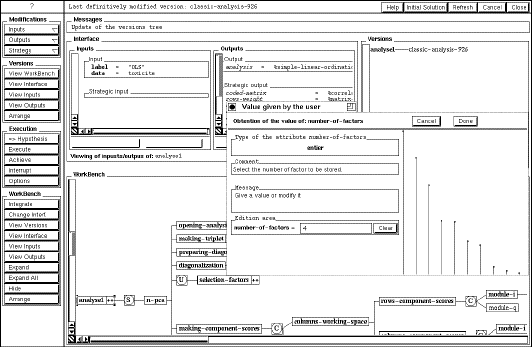
FIG. 2 (d'après [Willamowski 94]) - L'interface de Scarp.
On y voit en haut les entrées/sorties de la tâche en cours
d'exécution, en bas l'arbre de décomposition des tâches et
par dessus un interacteur demandant son avis à l'utilisateur.
L'<<exécution>> d'une tâche s'accomplit comme suit:
- une instance de la classe représentant la tâche est
créée;
- les entrées sont d'abord obtenues, soit par le flot de
données, soit par la définition de la tâche (à
l'aide des mécanismes d'inférence);
- la classification est utilisée pour déterminer, en fonction
des entrées, les tâches applicables;
- les entrées manquantes sont obtenues par demande à
l'utilisateur;
- si la tâche est une méthode, elle est exécutée,
sinon la décomposition est exécutée en revenant en (1)
pour chaque sous-tâche;
- les sorties sont obtenues grâce au flot de données et
validées par l'utilisateur.
Bien entendu, ce processus est non
déterministe, car la classification peut donner plusieurs
résultats et il peut y avoir des opérateurs de choix dans les
stratégies. Le système utilise donc des stratégies par
défaut et procède à un retour-arrière en cas
d'échec. En fait, le système est beaucoup plus versatile que cela
puisqu'il est conçu pour être mis à la disposition d'un
utilisateur qui peut, à tout moment, interrompre le processus, changer
un choix par défaut, ou un choix fait précédemment par
lui, et relancer l'exécution. Pour cela, il faut que l'utilisateur ait
à tout moment une image du processus en cours, ce qui est offert par
l'interface graphique (voir figure 2).
La sémantique opérationnelle de ce système a
été étudiée dans [
Crampé 94], elle
s'apparente clairement à celle de Prolog... qui se retrouve donc
intégré plus naturellement (que par des règles) au sein
des objets.
Shirka était à l'origine utilisable en mode alphanumérique
(et il l'est toujours). Mais très tôt le problème des
interfaces s'est posé. On a, dans un premier temps,
développé une interface permettant d'utiliser Shirka comme un
tableur alphanumérique (l'interface privilégiée de
l'époque; il est toujours livré avec
Shirka) [
Demuyter& 86].
Puis, avec la diffusion d'X-windows sont apparues les
interfaces graphiques que l'on connaît maintenant [
Cruypenninck& 92].
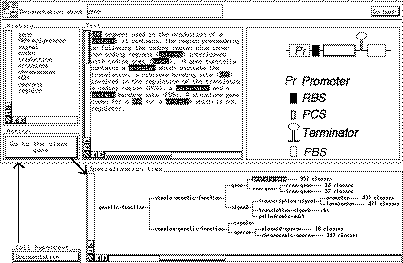
FIG. 3 (d'après [Euzenat 95a]) - Liaison Shirka-hypertexte
permettant de passer du texte aux objets et vice versa.
Mais l'expression de la connaissance sous un formalisme particulier, si elle
permet sa manipulation par un ordinateur, a ses limites. En particulier, elle
ne permet pas de tout exprimer et n'est pas forcément intelligible
à un utilisateur qui n'a pas participé à
l'élaboration de la base. Ceci a justifié l'adjonction à
Shirka d'un système d'hypertexte permettant d'exprimer informellement
des informations [Grivaud& 92]. L'aspect original du
système -- qui a profité de l'intérêt
porté aux hypertextes dans les années 80 -- est non seulement de
pouvoir accéder au texte à partir des éléments de
connaissance (classes, attributs...), mais aussi de pouvoir revenir aux
éléments de connaissance à partir de l'hypertexte (voir
figure 3).
C'est sous ces diverses formes que Shirka
a été utilisé dans un certain nombre d'applications.
L'inventaire des applications montre les
diverses utilisations de Shirka et
Scarp portées à notre
connaissance. Beaucoup d'entre elles ont été
réalisées indépendamment de l'équipe qui a
développé Shirka et
Scarp, et dont la contribution n'a
consisté qu'à assister par des conseils et à prendre en
compte d'éventuels problèmes.
Une telle utilisation d'un logiciel développé en laboratoire est
encourageante. Au delà du nombre, on peut cependant noter deux aspects
concernant ces applications:
- elles ont principalement été réalisées dans
des laboratoires de recherche, par des spécialistes du domaine: elles
n'ont donc pas bénéficié du support d'un
intermédiaire informaticien ou <<cogniticien>>, mais au
contraire du lien direct avec le <<producteur de connaissance>>.
- le choix de Shirka a pu être influencé par le fait qu'il
était distribué gratuitement (bien que des formalités
devaient être initialement remplies pour utiliser le
système).
Du premier point vient sans doute un tournant des
activités du projet Sherpa
vers <<ceux qui produisent la connaissance>>, c'est-à-dire
les utilisateurs dont le métier est d'exprimer la connaissance qu'ils
acquièrent (traditionnellement par des livres ou des cours),
plutôt que vers <<ceux qui sont chargés d'accoucher cette
connaissance>>. Cela passe, bien entendu, par une sémantique
plus claire (elle ne l'est jamais assez) du système, une
définition de cette sémantique et des outils confortables
d'exploitation.
Le Shirka actuel n'a pas beaucoup changé en 10 ans. Depuis longtemps une
nouvelle version est envisagée qui a pris le nom de Tropes en 1990.
Tropes [
Mariño 93;
Mariño& 90] reprend un
certain nombre d'idées fortes de Shirka tout en changeant radicalement
certains aspects. Les aspects conservés sont les suivants:
- La distinction classe/instance est renforcée par un
troisième niveau, le concept, qui permet de partitionner l'univers du
discours de manière étanche: ceci a des incidences sur la
signification et l'implémentation des objets.
- Le typage fort des attributs se voit renforcé par une disparition
des types primitifs (décrits au travers de types abstraits et par
conséquent extensibles) et par un système de normalisation de
types permettant de faire une classification de classes correcte
[Capponi 95].
- La connexion avec un système hypertexte repose simplement sur HTML.
En plus de ce qui a été présenté plus haut, Tropes
est capable de présenter la connaissance sous forme de documents HTML
à la volée (c'est-à-dire que Tropes se transforme en
serveur et engendre les pages à la demande au lieu de les stocker au
préalable).
Tropes ajoute à cela deux nouveautés
principales:
- la représentation des taxonomies de classes sous plusieurs points
de vue (inspirée de [Carré 89]), qui rend compte de la
multiplicité des approches possibles lorsqu'il s'agit de structurer un
ensemble d'objets [Mariño 93];
- l'utilisation d'un système de résolution de contraintes, en
remplacement des anciennes contraintes de Shirka, mais aussi en prolongement du
système de types [Gensel 95b].
Certains aspects de Shirka ont
été abandonnés, soit parce qu'ils n'ont jamais
été utilisés (règles), soit parce qu'il est
délicat de leur associer une sémantique s'intégrant dans
la philosophie générale du système (c'est le cas pour la
réflexivité qui ne s'accorde pas uniformément avec la
sémantique de la classification). Mais d'autres aspects
déjà abordés seront à poursuivre:
- le maintien du raisonnement et la gestion d'hypothèses qui
permettent de traiter un raisonnement disjonctif [
Gensel 90;
Gensel& 93] (le système de maintien du raisonnement
présenté plus haut constitue une expérience à
reconduire mais en reconsidérant son intégration au sein du
système de satisfaction de contraintes);
- la construction automatique de taxonomies par diverses méthodes
d'analyse de données [
Euzenat 93c] ou d'apprentissage symbolique
[Aguirre 89;
Valtchev& 95;
Bisson 95];
- l'intégration d'équations qualitatives sur le comportement
des objets;
- l'intégration de connaissances linguistiques sur la connaissance
afin de traiter la déconnexion entre le langage courant et le langage
standardisé dans une base de connaissance [
Lemaire 95c] (ceci
permet aussi de traiter le multi-linguisme);
- la conception de mécanismes de construction coopérative de
bases de connaissance [Euzenat 95a].
Tropes, ainsi que sa
documentation, sont disponibles ici
(voir aussi https://hytropes.inrialpes.fr).
L'exposé qui précède n'introduit pas d'originalité.
Son but est de récapituler l'évolution d'un langage sur 10 ans.
L'évolution technique de Shirka se traduit aussi par une
évolution théorique.
Le parti-pris de déclarativité va dans le sens de l'histoire et
s'est révélé payant en terme d'utilisabilité par
les applications. Celui du <<tout objet>> a montré ses
limites (réflexivité, règles, TMS) mais aussi ses
avantages (filtres, classification, tâches). Ce dernier point est donc
à évaluer de manière très précise avant de
le réutiliser. On peut dire que plus une notion (ici objet) a
d'utilisations différentes et variées, moins elle a de
signification propre. Ainsi, l'exploitation tout azimut d'un concept --
perçu comme un gage de sa généralité -- n'est pas
forcément si positive. Par exemple, l'interprétation des objets
donnée ci-dessus autorise la classification telle qu'elle a
été présentée mais devrait interdire l'utilisation
des objets Shirka en tant que dépendances dans le TMS (voire même
en tant que tâches). Mais pour s'en rendre compte, il est
nécessaire de s'entendre au préalable sur la sémantique
des notions utilisées. C'est pourquoi il est apparu petit à petit
(nous ne sommes pas les premiers à nous en rendre compte, voir par
exemple [Levesque& 87]) que la notion de
déclarativité utilisée initialement devait être
remplacée par celle d'interprétation. D'une manière
générale, ces principes se sont donc dégagés au
cours de ces dix ans comme antagonistes. Mais dix ans, c'est à la fois
trop -- en tout cas suffisant pour se rendre compte de cet antagonisme -- et
trop peu -- car le développement d'une sémantique englobant la
totalité du monde objet (y compris la programmation) n'a pas eu le temps
de voir le jour.
Au delà des aspects conceptuels, les utilisations d'un système
comme Shirka montrent qu'il y a réellement un besoin. Mais ces outils
sont principalement utilisés par des ingénieurs ou des chercheurs
non informaticiens: ils doivent donc bénéficier d'une
simplicité d'utilisation (uniformité) et d'une sémantique
claire.
Les auteurs remercient Roland Ducournau et Amedeo Napoli pour leur exigence de
précision et de vérité historique, ainsi que
Jean-François Perrot pour être le premier à avoir
rédigé une mise en perspective des travaux du projet Sherpa.
Ici ne figure que la partie de la bibliographie de l'article original qui
n'a aucun rapport avec le projet Sherpa.
Les références concernant les applications de
Shirka se trouvent ici alors que celles
signées par les membres du projet Sherpa
sont répertoriées là.
- [Aikins 83]
- J. Aikins. Prototypical knowledge for expert systems.
Artificial intelligence 20:163-210 83
- [Albert 84]
- P. Albert. KOOL at a glance. Actes 6th ECAI, Pisa,
IT, p345 84
- [Bobrow& 81]
- D. Bobrow et M. Stefik. The LOOPS manual.
Memo KB-VLSI-81-13, Xerox PARC, Palo Alto, CA US 81
- [Bobrow& 77]
- D. Bobrow et T. Winograd. An overview of KRL:
knowledge representation language. Cognitive science 1(1):3-45 77
- [Brachman& 85a]
- R. Brachman et J. Schmolze. An overview of
the KL-one knowledge representation system. Cognitive science
9(2):171-216 85
- [Brachman 79]
- R. Brachman. On the epistemological status of semantic
networks. Dans N. Findler (éd.). Associatives networks:
representation and use of knowledge by computers. Academic Press, New-York,
NY US, pages 3-50 79
- [Brachman 83]
- R. Brachman. What is-a is and isn't: an analysis of
semantics links in semantic networks. IEEE Computer 16(10):30-36 83
- [Brachman 85]
- R. Brachman. "I lied about the trees" or, defaults and
definitions in knowledge representation. AI magazine 6(3):80-93 85
- [Carré 89]
- B. Carré, Méthodologie
orientée-objet pour la représentation des connaissances: concepts
de points de vue, de représentation multiple et évolutive,
Thèse d'informatique, université de Lille, FR 89
- [Chailloux 83]
- J. Chailloux. Le_Lisp 80, version 12: le manuel de
référence. Rapport technique 27, INRIA Rocquencourt, FR 83
- [Chandrasekaran 86]
- B. Chandrasekaran. Generic tasks in knowledge-based
reasoning: high-level building tools for expert-system design. IEEE
Expert 1(4):23-30 86
- [Cointe 85]
- P. Cointe. Le modèle objVlisp: une plate-forme pour
l'expérimentation des formalismes objets. Actes 5ième
RFIA, Grenoble, FR, pages 737-754 85
- [Doyle 79]
- J. Doyle. A truth maintenance system. Artificial
intelligence 12(3):231-272 79
- [Ducournau& 86]
- R. Ducournau et J. Quinqueton. YAFOOL:
encore un langage objet à base de frames! version 2.1. Rapport
technique 72, INRIA, Rocquencourt, FR 88
- [Ferber 83]
- J. Ferber. MERING: un langage d'acteurs pour la
représentation et la manipulation des connaissances. Thèse
d'informatique, université Pierre et Marie Curie, Paris, FR 83
- [Fikes& 85]
- R. Fikes et T. Kehler. The role of frame-based
representation in reasoning. Communication of the ACM 28(9):904-920 85
- [Granger 88]
- C. Granger, An application of possibility theory to object
recognition, Fuzzy sets and systems 28(3):351-362 88
- [Goodwin 79]
- J. Goodwin. Taxonomic programming with KLONE.
Rapport de recherche LITH-MAT-R-79-5, Linköping university,
Linköping, SE 79
- [Haton& 91]
- J.-P. Haton, N. Bouzid, F. Charpillet, M.-C.
Haton, B. Lâasri, H. Lâasri, P. Marquis, T. Mondot et A. Napoli.
Le raisonnement en intelligence artificielle. InterÉditions,
Paris, FR 91
- [Hulot 83]
- J.-M. Hulot. Ceyx: a multi-formalism programming
environment. Rapport de recherche 210, INRIA, Rocquencourt, FR 83
- [INRA88]
- Le projet CHIMENE, document ronéoté, INRA,
Jouy-en-Josas (FR) 88
- [Laurière 82]
- J.-L. Laurière. Représentation et
utilisation des connaissances. Techniques et science informatique
1(1):25-42 & 1(2):109-133 82
- [Levesque& 87]
- H. Levesque et R. Brachman. Expressiveness and
tractability in knowledge representation and reasoning. Computational
intelligence/intelligence informatique 3(2):78-93 87
- [Minsky 74]
- M. Minsky. A framework for representing knowledge.
Rapport technique AI-memo 306, MIT, Cambridge, MA US, (rep. dans P. Winston
(éd.). The psychology of computer vision. Mac
Graw-Hill, New York, NY US, pages 211-277 75) 74
- [Roberts& 77]
- R. Roberts et I. Goldstein. The FRL
manual. Rapport de recherche AIM-409, MIT, Cambridge, MA US 77
- [Roche 84]
- C. Roche. LRO: génération de systèmes
experts. Thèse d'informatique, INPG, Grenoble, FR 84.
- [Wielinga& 86]
- B. Wielinga et J. Breuker. A model of
expertise. Actes 7th ECAI, Brighton, GB, pages 306-318 86
- [Williams 84]
- C. Williams. ART: The advanced reasoning tool,
conceptual overview. Inference Corporation, Los Angeles, CA US 84
- [Winston& 81]
- P. Winston et B. Horn. Lisp. Addison-Wesley,
Reading, MA US 81
- [Wright& 83]
- J. Wright et M. Fox. SRL/1.5 user manual.
Carnegie-Mellon university, Pittsburg, PA US 83
Mis-à-jour par Jerome.Euzenat@inria.fr le 14/12/2021