Logiciel
Les logiciels développés mettent en oeuvre les modèles
de connaissances et de raisonnement étudiés au sein du
projet Sherpa.
Certains sont disponibles sur ce site. Ces logiciels ont
été utilisés dans de nombreuses
applications. Ils comprennent:
- Shirka, un système de
représentation de
connaissance par objets;
- SaMaRis, un système de maintien du
raisonnement générique;
- Scarp, un système coopératif
d'aide à la
résolution de problèmes;
- PowerTask, un outil de résolution de
problèmes à base de tâches;
- Troeps, un système de
représentation de
connaissance par objets multi-perspectives;
- Amia, un environnement de modélisation et simulation à base de
connaissance.
Le contexte et l'évolution du développement de ces logiciels
sont décrits dans l'article
<<Shirka, 10 ans, c'est
Tropes>> disponible ici en
version HTML.
Shirka est un système de représentation de connaissance par
objets. Ses traits principaux sont la présence d'un mécanisme
de classification original, la notion de filtres et une interface
hypertexte. Il est développé en Lisp (Le-Lisp 15) et utilise
le générateur d'interfaces graphiques Aïda. Shirka
a été utilisé dans de nombreuses applications (Elsa, Eve,
Gide, Coligene, MultiMap, Édora, Sadig, Safir...) et est utilisé par le
système Scarp.
Shirka peut être
obtenu à l'adresse
shirka.tar.gz
(544 Ko) et sa documentation est accessible sous
manuel-shirka.ps.gz.
Des publications sur le sujet sont
[Rechenmann 85] et
[Rechenmann& 89b] (en anglais).
SaMaRis est un système de maintien du raisonnement qui peut
être adapté au type de "valeurs de vérités"
utilisées par le raisonneur (qui peuvent être très
variées). Il inclu aussi une interface vers les "raisonneurs"
ainsi qu'une interface graphique permettant de manipuler interactivement
le raisonnement.
SaMaRis n'est plus disponible.
Les publications s'y rapportant sont
[Euzenat 91a] et
[Euzenat& 91b].
Scai est l'ancêtre de Scarp.
Il a été conçu au dessus de
Shirka et a été utilisé dans
l'application Danaïde. Il n'est
plus disponible.
Dans les approches classiques de planification et de résolution de
problèmes, l'objectif est le développement de
systèmes autonomes,
fonctionnant pratiquement sans intervention de l'utilisateur.
L'interaction entre
l'utilisateur et le système est dans ces cas très
limitée : l'utilisateur est réduit au rôle de
fournisseur de données. Cependant, envisager une résolution
automatique
de problèmes par des systèmes à base de connaissances
est en
général irréaliste :
- certains problèmes nécessitent impérativement
une intervention
de l'utilisateur;
- les décisions prises pendant la résolution d'un
problème ont souvent un caractère hypothétique et
doivent pouvoir
être remises en cause;
- un utilisateur peut ainsi avoir des connaissances plus
complètes que le système à base de connaissances et
doit pouvoir
les mettre en oeuvre.
C'est pour répondre à l'ensemble de ces besoins que la notion
de Système Coopératif d'Aide à la Résolution de
Problèmes (SCARP) a été proposée. Dans un tel
système, le processus de résolution n'est pas
géré de façon autonome par le système, mais en
coopération avec l'utilisateur. Pour les problèmes avec une
stratégie de résolution bien connue, le système peut
gérer le processus de résolution de manière
automatique, prenant en compte simplement les interactions obligatoires
avec l'utilisateur. Mais l'utilisateur peut intervenir à tout
moment dans le processus
de résolution pour en modifier les caractéristiques.
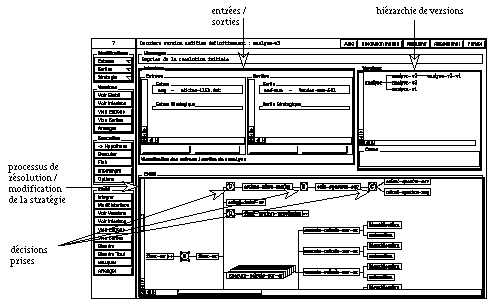
Figure : La fenêtre de base de Scarp.
Cette fenêtre donne accès aux entrées / sorties de la
tâche à résoudre et visualise graphiquement
l'état d'avancement du processus de résolution ainsi que
toutes les décisions prises pendant la résolution. La partie
montrant la hiérarchie de versions permet d'accéder aux
versions associées à une tâche et ainsi de naviguer
entre elles.
Le système Scarp permet de développer de tels
Systèmes Coopératifs d'Aide à la Résolution de
Problèmes. Il inclut :
- la représentation par objets
Shirka des
connaissances de résolution de problèmes;
- la modélisation par tâches des stratégies de
décomposition d'un problème en sous-problèmes plus
élémentaires et le choix de la stratégie
adaptée par classification;
- la gestion de différentes versions du processus de
résolution;
- l'exploration interactive de nouvelles tâches par l'utilisateur.
Le mécanisme de résolution repose sur une alternance de
phases de
décomposition et de caractérisation (par classification) de
tâches. Scarp a été utilisé dans plusieurs
applications à l'extérieur du projet
(Anaïs,
Said,
Myosys et
Slot).
Scarp est accessible par
scarp-v2_23.tar.gz
et sa documentation se trouve sous
docs.tar.
Des
publications en rapport sont
[Willamowski 94b] et
[Willamowski& 94] (en
anglais).
L'environnement PowerTasks a été construit dans le cadre d'un transfert
technologique auprès de la société
Ilog. Cet outil générique de
résolution de
problèmes a été conçu autour d'un nouveau modèle à objets et tâches
issu des
expériences précédentes (voir ci-dessus Scai et Scarp). PowerTask
dispose d'un moteur de résolution associant à chaque tâche les méthodes possibles
et d'une interface graphique qui permet à l'utilisateur :
- de visualiser toutes les étapes d'une stratégie au cours de son exécution,
- de spécifier les paramètres et les choix nécessaires à cette exécution,
- de reprendre une exécution à n'importe quel endroit, ce qui l'autorise à
émettre, tester et valider plusieurs hypothèses en parallèle,
- de modifier une stratégie en modifiant ou ajoutant des sous-tâches.
PowerTask étant un produit de la société Ilog, il n'est pas librement disponible.
Troeps est un système de représentation de connaissances
à objets et points de vue multiples, conçu
et implémenté depuis plusieurs années par le projet
SHERPA.
Troeps était précédement nommé Tropes mais a changé son nom pour des
raisons juridiques en 1998.
Il peut être considéré comme le successeur de Shirka dont il reprend les principaux traits
caractéristiques en y ajoutant la notion de multiples taxonomies sur
le même ensemble d'objets, de types de
données abstraits et de satisfaction de contraintes.
C'est autour de ce
système que sont capitalisés les différents
développements logiciels menés dans le
projet, eux-mêmes matérialisant des résultats de
recherches fondamentales. Troeps permet ainsi d'expérimenter nos
résultats à travers son utilisation dans
plusieurs applications
(Knife, SToRIA et
Lipsi).
Le système Troeps a été complété par
une version serveur de connaissance. Ce serveur permet
d'accéder aux objets
de la base au travers du Web comme s'il s'agissait de pages HTML.
Cependant la
puissance du modèle à objets permet de faire des
requêtes structurées sur ces
objets qui dépassent la recherche usuellement disponible sur un
site Web. Un tel
serveur de connaissances permet par ailleurs de structurer une base de
documents
(hypertextuels ou non) autour de la connaissance formalisée dans
les objets.
La version 1.2 de Troeps actuellement disponible ne contient pas le
système de satisfaction de
contraintes mais toutes les autres
fonctionnalités sont disponibles. En particulier il comprend
maintenant :
- un système de types
sophistiqué sur lequel s'appuient les opérations de
vérification de types, de classification et de catégorisation (voir ci-dessous).
- un éditeur de base de connaissances au travers du protocole HTTP
qui permet la protection par mot de passe des bases
ainsi qu'un paramétrage des serveurs (éditables/non éditables).
- un lexique qui permet de décrire les définitions de termes ainsi que de nombreuses
relations entre ceux-ci (synonymie, antonymie, hyperonymie...). Il permet
d'indexer les noms des entités de la base de connaissances. Le lexique est
manipulable à travers le même type d'interface que la base de
connaissances. Il est ainsi naturel de naviguer dans l'univers des objets ou l'univers des
termes et de passer de l'un à l'autre.
- un environnement de catégorisation (ou "clustering") qui permet de construire de
manière automatique des hiérarchies de classes à partir des objets disponibles.
Ce module utilise actuellement des méthodes classiques de catégorisation
ascendante (plus proches voisins) s'appuyant sur les
mesures de dissimilarité
développées spécifiquement pour les objets et utilisant les types abstraits du
module de type. Il fournit des descriptions synthétiques des classes obtenues.
- un mécanisme de révision ;
- la connexion avec Co4.
Troeps est
développé en Ilog Talk et
peut être utilisé comme une bibliothèque Unix.
Troeps est accessible par
current.tar.gz
il occupe 20Mo décompressé (10Mo par portage) et 4Mo
compressé. Sa documentation se trouve sous
troeps-manual.ps.gz.
Des démonstrations et la documentation en-ligne sont accessibles
sous http://co4.inrialpes.fr.
Des publications en rapport (mais déviant
quelque peu du logiciel implémenté sont
[Mariño 93] et
[Mariño& 90] (en
anglais). Des informations sur l'aspect serveur de connaissance se trouvent sous
[Euzenat 96a] et
[Euzenat 96c] (en anglais et HTML)
Si vous avez un problème, ne vous exclamez pas "Que le grand
Troeps m'étripe!", envoyez plutôt un mail à
troeps@inrialpes.fr.
Développé en collaboration avec l'université Pierre
Mendès France de Grenoble,
Amia est un logiciel pour la modélisation et la simulation à base de connaissances.
L'objectif visé à travers ce logiciel est double. Le premier est d'étudier comment
améliorer l'intelligibilité et la généralité des modèles numériques par l'apport et
l'exploitation de connaissances de nature symbolique. De telles connaissances
s'avèrent en effet nécessaires pour :
- exprimer les propriétés et les relations non-numériques entre les
composants du système modélisé;
- formaliser les hypothèses sous-tendant les équations d'un modèle et rendre ainsi
explicite le contexte de validité de ce modèle;
- pouvoir construire différentes variantes d'un modèle et formaliser le choix de la
variante adaptée en fonction du contexte de simulation.
Pour ce faire, Amia dispose d'un langage de modélisation algébrique, un
formalisme d'écriture des équations proche des notations algébriques utilisées en
mathématiques, qui a été étendu pour permettre l'expression des connaissances ci-dessus.
Le second objectif est l'expérimentation des algorithmes de simulation adaptés à ce
type de langage qui ont été développés dans le projet. Ils sont en cours de
validation sur des applications complexes.
Le protocole de Co4 a été
implémenté (en C) sous la forme d'une bibliothèque.
Celle-ci dispose d'outils de manipulation des éléments du protocole
(soumissions à examiner, votes, etc.) accessibles depuis un client HTTP.
Le protocole peut être connecté à différents types d'applications et a été
connectée à Troeps de manière à pouvoir
soumettre directement la connaissance contenue dans les bases. Le protocole sera
utilisé dans le contexte de la mémoire technique.
Cette implémentation repose sur KQML,
un langage d'interaction entre bases de connaissances distribuées
indépendant du langage de représentation. Elle utilise une
extension de l'interface KAPI (2.6e), développée par Lockheed-Martin.
Les extensions de KAPI nécessaires ont été développées initialement
en collaboration avec l'équipe d'A. Quintero (université des
Andes, Bogota).
La version 1.0 du protocole de Co4 est disponible en
current.tar.gz
Il occupe 15Mo (décompressé and 2Mo compressé).
Sa documentation est sous:
co4-manual.ps.gz.
http://co4.inrialpes.fr est un site Web
dédié à Co4.
Deux publications pertinentes sont:
[Euzenat 95a] et
[Euzenat 97a] (toutes deux en anglais).
https://www.inrialpes.fr/sherpa/soft-fra.html
Last update 15-DEC-2021
![[RECHERCHE]](share/gif/ib_rech.gif)
![[VALORISATION]](share/gif/ib_diff.gif)
![[PERSONNEL]](share/gif/ib_people.gif)
![[PUBLICATIONS]](share/gif/ib_publi.gif)
![[APPLICATIONS]](share/gif/ib_appli.gif)
![[INRIA]](share/gif/ib_inria.gif)